Policy function approximations (PFAs)
Policy function approximations are the simplest, and most widely used, class of policies for making decisions. They include any function that directly maps the information in the state variable to a decision, without solving an embedded optimization problem. In fact, they are the only one of the four classes of policies that do not require solving an optimization problem.
PFAs include any function that might be used in machine learning, which means they include:
- Lookup tables — rules of the form “if in this state, take this action.”
- Parametric models — linear and nonlinear models, including neural networks.
- Nonparametric models — local approximations that might be constant, linear, or nonlinear and capture only local behavior. Examples: kernel regression, radial basis functions, splines, support vector machines, deep neural networks.
Lookup tables
The best way to describe lookup tables is with rule-based systems:
“If in this state, take this action.”
This was “artificial intelligence” in the 1970s and 1980s, and formed the basis of so-called expert systems. This was promoted with the same claims we hear about “AI” today, with projections that computers were going to take over the world. By 1990 this effort was viewed as a complete failure — which was not true: rule-based systems remain widely used today.
The problem with rule-based systems is that state variables are invariably vectors. Imagine the state variable capturing attributes of a patient: gender, age, weight, smoker?, blood pressure, cholesterol, cancer?, and so on. The condition “if in this state” has to be broken down into a number of nested “if this state variable has this value,” which explodes the number of possible combinations. This is a classic case of the curse of dimensionality.
Linear models
A linear model, also known as a “linear decision rule” — or to the optimal-control community, an “affine policy” — simply means that the policy is linear in the parameters. Let $S_t$ represent all the information available at time $t$. We are not necessarily going to use all this information to make a decision, so let:
\[\phi_f(S_t) = \text{a ``feature'' } f \text{ that we extract from the information in } S_t\]where we have a set $\mathcal{F}$ of features.
We can then write our policy as
\[X^\pi(S_t \mid \theta) = \sum_{f \in \mathcal{F}} \theta_f \phi_f(S_t).\]The policy $\pi$ contains the set of features (where we also use $f$ to describe the structure of the policy), along with the parameters $\theta$.
An example of a linear decision rule is the PID controller (PID stands for proportional, integral, derivative), widely used when controlling temperature, flows of liquids or gases, and administering drugs such as insulin. Let:
- $r_t$ = target value we are trying to hit (temperature, flow, blood sugar),
- $y_t$ = actual value,
- $T_s$ = length of time step,
- $e_t = r_t - y_t$ = error (proportional),
- $I_t = I_{t-1} + T_s e_t$ = sum of errors (integral),
- $D_t = (e_t - e_{t-1}) / T_s$ = derivative,
- $S_t = (y_t, e_t, I_t, D_t)$ = state variable.
The PID control policy is then
\[X^\pi(S_t \mid \theta) = \theta^{\text{prop}} e_t + \theta^{\text{integral}} I_t + \theta^{\text{dif}} D_t.\]Nonlinear models
A popular policy in reinforcement learning is the Boltzmann policy, which chooses a discrete action $a$ according to the Boltzmann probability distribution:
\[A^\pi(S_t \mid \theta) = a \quad \text{with probability proportional to} \quad \frac{e^{\theta C(S_t, a)}}{\sum_{a'} e^{\theta C(S_t, a')}}.\]A different style of “nonlinear” policy uses rule-based regions, such as a policy for buying energy when prices are below $\theta^{\text{low}}$ and selling when prices are above $\theta^{\text{high}}$:
\[X^\pi(S_t \mid \theta) = \begin{cases} +1 & \text{if } p_t < \theta^{\text{low}} \\ \phantom{+}0 & \text{if } \theta^{\text{low}} \le p_t \le \theta^{\text{high}} \\ -1 & \text{if } p_t > \theta^{\text{high}} \end{cases}\]Note that this is technically nonlinear — specifically piecewise linear — parameterized by $\theta$.
A final form of nonlinear policy is (of course) a neural network, depicted below.
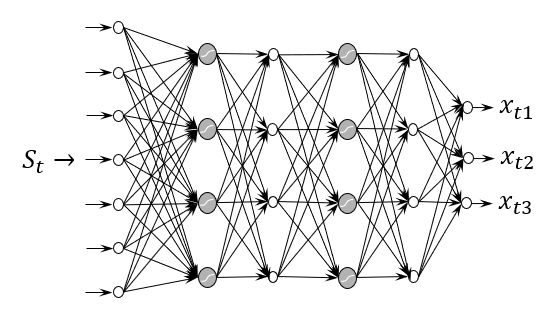
The modern (and very deep) neural networks can handle very high-dimensional state variables as input, and can produce high-dimensional vector outputs. This model was used by Amazon to plan inventories for 10,000 products — meaning $x_t$ had 10,000 dimensions — while the inputs $S_t$ consisted of any information that might be relevant in the planning of any of the 10,000 products.